
A few Liipers (Brian, David, Laurent and I) went to the ElasticSearch training in Paris at the beginning of July. I had worked with Lucene before but had close to no experience with ElasticSearch and my team is working on a big ElasticSearch project so I thought it wouldn't hurt too much if I go… Beside, I was curious to find out what the hype is all about.
“It scales”
I was mostly interested to know how ElasticSearch scales and performs under a very high number of queries. I'll try to summarize the findings below.
ElasticSearch is a fast and scalable, distributed search engine based on Lucene. One can define indexes that are horizontally split into shards. Shards are then automatically distributed by ElasticSearch on different nodes and can be replicated to be resilient in case of failure (using replicas). An ElasticSearch node is actually only a java process and can be run anywhere (nothing prevents you from having 2 nodes running on the same machine). Nodes discover themselves automatically via IP multicast or unicast to form an ElasticSearch cluster.
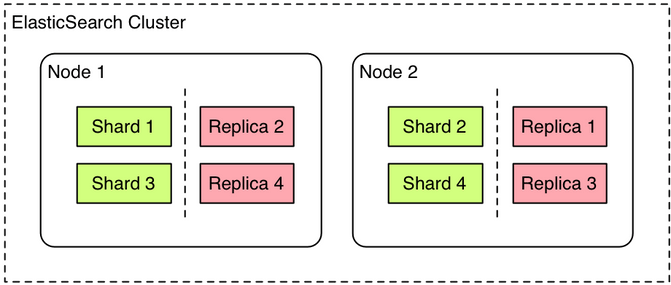
Example of a cluster with 2 nodes holding one index with 4 shards and 1 replica shard
In theory, it scales in both data capacity and number of queries simply by adding nodes to the cluster. When a new node is added to a cluster, ElasticSearch will automatically reassign some shards to the new node, reducing the load on existing node by putting it on the new one. All this happens automatically. An ElasticSearch node already takes advantage of multi-core CPUs so there isn't much to do there.
Node Roles Load Balancing
An ES node can play any, two or all of the 3 following roles:
- Master: master nodes are potential candidates for being elected master of a cluster. A cluster master holds the cluster state and handles the distribution of shards in the cluster. In fact, it takes care of the well-being of the cluster. When a cluster master goes down, the cluster automatically starts a new master election process and elects a new master from all the nodes with the master role.
- Data: data nodes hold the actual data in one or more shards, which are actually Lucene indexes. They are responsible for performing indexing and executing search queries.
- Client: client nodes respond to the ElasticSearch REST interface and are responsible for routing the queries to the data nodes holding the relevant shards and for aggregating the results from the individual shards.
By default, ElasticSearch nodes are configured to play the 3 roles, master, data and client. In an ElasticSearch cluster, there is usually more than one client node, and as they all offer a REST API, the client nodes can actually be used as load balancers, which eliminates the need of using an external load balancing mechanism. When a request is sent to an ElasticSearch cluster, the client node that receives the request always is the one that aggregates the results (that is never re-routed to another client node).
A proposed architecture do properly load balance requests from a web application (as we have in our project) is therefore the following:
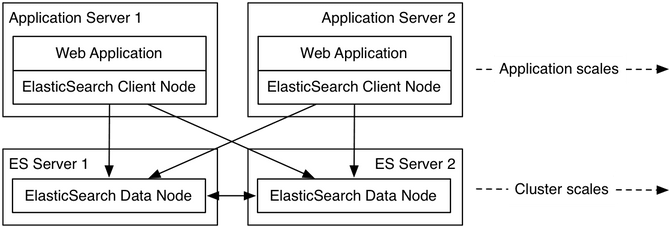
Example of 2 application servers using ElasticSearch data nodes by talking to an embedded client on the same server
It is also recommended to keep a long live HTTP requests to the client nodes, as it will spare creation and deletion of a connection for each request.
Fast Data Nodes
As the data nodes hold the Lucene indexes, they should be configured to take the biggest advantage of Lucene's capabilities. I've summarized below the biggest learnings from the training:
“Make sure the file system cache is used by the ElasticSearch process”
As Lucene relies a lot on the file system cache for performance, it is highly recommended to leave at least half the memory free for the file system cache (make sure ES_HEAP_SIZE doesn't go above half the available memory). This also means that there should not be a bunch of other processes fighting for file system cache resources (e.g. a MySQL database). The more processes the more chances a file read will go to the disk and therefore slow the Lucene operations down.
“Make sure the process does not swap.” (cf. ElasticSearch reference guide)
The disk should only be used to read and write index files, if the process also uses it to swap the memory, the performance will degrade. A way to do that in Linux is to set bootstrap.mlockall to true.
“Watch the java pointers”
That one has to do with using Java in general. On a 64bit system, the ordinary object pointers (pop) can take up to 8 bytes of memory to be able to address the whole memory. However, the pointers can be compressed to take up only 4 bytes when the heap size is set to under 32gb. This is what the official Oracle doc says:
Compressed oops is supported and enabled by default in Java SE 6u23 and later. In Java SE 7, use of
compressed oops is the default for 64-bit JVM processes when -Xmx isn't specified and for values of
-Xmx less than 32 gigabytes. For JDK 6 before the 6u23 release, use the -XX:+UseCompressedOops
flag with the java command to enable the feature.Therefore if ElasticSearch runs on a JDK before the 6u23 release, make sure you use -XX:UseCompressedOops flag if your heap size is less than 32gb.
“Files, files, files” (cf. ElasticSearch reference guide)
The ElasticSearch process can use up all file descriptors in the system. If this is the case make sure the file descriptor limit is set high enough for the user running the ElasticSearch process. Setting it to 32k or even 64k is recommended (you'll have to Google how to do that one …)
“Disk, disk, disk”
Medium and big hardware make more economical sense. Because of the way Lucene uses files (elaborate), SSDs are particularly suited, it is recommended to use RAID for performance only, and take advantage of ElasticSearch replicas for fault tolerance.
“Memory, memory, memory”
The optimal RAM size for a data node can be calculated by taking the total of all index files.
“Don't use facets on analyzed fields”
Facets on analyzed fields take a lot of memory. If the OutOfMemory error occurs, increase heap size or add more nodes…
Master Nodes, Shards, Replicas and the Cluster State
ElasticSearch indexes are split horizontally in shards and each shard is replicated in a configurable number of replicas. By default, the number of shards is set to 5 and the number of replica to 1, meaning an index will have 5 primary shards and 5 replica shards (1 replica for each primary shard). What this means is: 1 node is allowed to fail and the cluster will still contain the entire index (or: if more than 1 node fails, it is not guaranteed that the whole index is still present). If the number of replica is set to 2, then a maximum of 2 nodes can fail at the same time without any impact on data integrity (of course the cluster has to have more than 2 nodes in total…)
The ElasticSearch master is the one that is responsible to keep the integrity and status of the cluster. When a node is added to the cluster, it makes sure some shards are copied over to that node as soon as possible. When a node disappears from the cluster, it makes sure that missing shards are replicated on the existing nodes.
Nodes discover themselves using either multicast or unicast. It is highly recommended to use unicast instead of multicast for node discovery. Each node doesn't need to know about all other nodes of the cluster, since once a new node discovers another node, it will ask the master to provide the information about the whole cluster to the new node directly.
One (or two) more thing(s) …
Both the number of shards and the number of replicas can be configured independently for each index. The number of replicas can be changed at runtime, but the number of primary shards is defined when the index is created and cannot be changed, which raises the question: “How do I set the optimal number of shards for my application ?”. Well, there is no answer and that's in my opinion (a lot of participants decided to agree on that) the biggest limitation of ElasticSearch at the moment. Resizing the shards when the cluster is in operation is a tedious process, one way to do it is to setup a new cluster, create an index with the desired number of shards and copy the old index over to the new one. That operation is lengthy and no writes can be allowed when copying the data (which makes it not really realistic for big, rapidly changing indexes).
One alternative is to set the number of shards to a very high number. That is not recommended since each shard takes quite some overhead to maintain a Lucene index and, the smaller the shards, the bigger the overhead. They gave us some sort of formula to calculate the maximum shard size, and based on that, you can infer the number of shards you need if you know the size of your index (number_of_shards = index_size / max_shard_size). Here it is:
- Use one shard and start loading it with data
- When queries start to slow down and become too slow for you, the max capacity on that hardware is reached.
Another feature that they are working on is the possibility to easily backup and restore an index. That hopefully will help better manage a cluster. The technology is still young so it is understandable that the management capabilities are not yet up to the task compared with established solutions.
Memory on Client Nodes
One of the focus of the future ElasticSearch releases is to improve the memory consumption, above all on the client node. The client node is responsible for gathering the responses of the data nodes and for sorting among others. Those operations happen entirely in memory for now, which can lead to memory leaks if the entire result set doesn't fit there. The solution in that case is to increase the heap size of the client nodes. Future ElasticSearch versions will also try to use files take advantage of the file system cache, just like Lucene does.
Summary
ElasticSearch seems like a good, scalable technology and I'm looking forward to seeing it in full use with the current project. It seems like most of the things we learned at the training regarding performance and live operations are not really officially documented, which makes the training very valuable. The lessons from the trainings are the following:
- Java Heap should be big, but not too big
- Client nodes can be used as load balancers
- Watch out for the number of shards
Keep reading for more infos as soon as the project goes live !