
Data mining using machine learning (ML) is a field that always fascinated me. You give an learning system millions of collected data, and it outputs back unexpected insights, that can help you focus on what matters, make you drop things that don't work, clears mystery from your customers behaviors and potentially reorient your company strategy.
It's compelling, but that makes you imagine the machine is doing the hard job … Of course not, the machine remains stupid, as always. Data mining is a long iterative process that requires a good load of intuition and a deep understanding of machine learning algorithms. However, it remains more accessible and fun than statistics to experiment because of its intrinsic empirical approach – sorry for feeding what's already being an unfair preconception that favor ML trend over statistics since decades…
I've been longing to put in practice my learning in that field with Google Analytics (GA) data. What more can ML offer in addition to the great analysis features Google Analytics provides ? Is it even possible? Suspecting that GA is not designed for that, I started a short experiment to explore this potentiality.
In this article – addressed to GA novices and ML enthusiasts – I will give a basic introduction about the requirements and benefits of ML, and list some constraints with GA.
In a future blog-post (edit : here), I will share my findings on how to quickly get machine learn-able traffic data, describe the technicalities of the exploration, and provide the minimum to let you do your own experiments.
Looking for a job?
Let's imagine a web site, like the Liip blog on which you are presently. And a visitor like you, reading this blog-post. Since Liip almost always has some open positions, we want to make sure that if you're a developer, you won't switch on your next data mining article before you've visited our open positions. If not, then you might well be a future client and thus interested to know about our service offering and expertise.
ML could help us to create a decision model to predict how much of a developer you are according to your attributes (ex : region, browser, visiting hours).
Our Google Analytics account contains thousand of examples where a visitor ended up visiting our job page, or not. That's food for an automatic learner!
One step beyond Google Analytics
Reviewing the audience profile that visited our job page can be done easily with GA. So what can ML bring to us ?
Using GA reports for trying to predict some something could be tempting. But statistically wrong. Let's try to figure out why.
First, let's see an example of GA report on people accessing the job page. This can be generated with GA query explorer:
| Browser | Operating System | Country | Sessions |
|---|---|---|---|
| Chrome | Macintosh | Switzerland | 305 |
| Chrome | Windows | Switzerland | 301 |
| Firefox | Macintosh | Switzerland | 186 |
This is sufficient to let you know the best ranking of combination for those four visitors characteristics (called dimensions). This report tells you that among people accessing the job page, the more popular combination of visitor characteristics is (“Chrome”, “Macintosh”, “Switzerland”).
However, it doesn't mean that a new visitor having those characteristics is likely to access the job pages. Indeed, this characteristics triplet is maybe not the best to discriminate the “job page accessed” case and “job page not accessed” case.
That's where machine learning can help.
How to teach a machine ?
Machine learning food
| **Note**
This article will only cover the minimal concepts in ML to understand our use case. For an introduction on ML, have a look on this well made visual introduction to machine learning. |
With machine learning you will be able to produce a ready-to-use decision tree for guessing the profile of visitors.
To do that, you need lot of historical data. To enable the machine to learn, each of those data must be associated with the correct classification (in our example: developer, or not developer). Here's a visual representation of the ML training process, with a possible resulting tree:
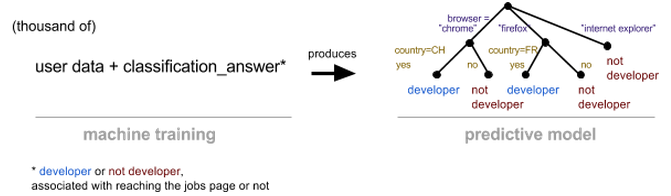
The more occurrences and attributes you have, the better it is.
Google Analytics is not ML friendly
Instead of occurrence based data usable to train a predictive model, GA will provide aggregate data which represents statistics on your traffic given a period :
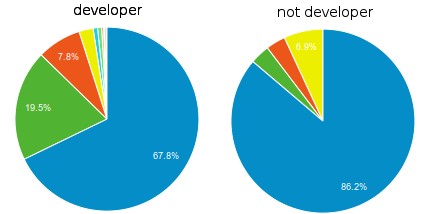
We'll see in a future blog-post how to query GA to get occurrence based reports in order to cope with this problem.
In addition to that, GA will be limited to get the many occurrences and attributes that makes a ML algo satisfied. You will have the following limitations:
- query can have maximum 7 dimensions
- query can be include maximum 90 days when using segments
- reports limited by 10'000 rows
However you can find ways to programmatically merge sequential queries to walk around those obstacles (in progress in my free time).
The data mining process
Once you get compatible data, you just feed a ML software and get interesting results !
not really…
After producing your first decision tree, you might get some doubts about the results, or raise new questions about the data relations. Also, you will question the usability of your raw data, and transform / enrich them if they don't make sense for prediction. To explore your assumptions, clean your doubts, or improve your predictive model performance, you will engage an obsessional and compulsive (yet interesting) iterative process which could be represented this way:
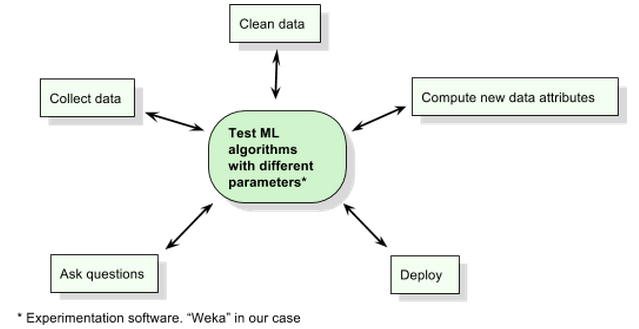
At the center of this process, comes an experimentation technology that will drive your research. In our case we used Weka. It's developed by the university of Waikato and it's open source. Weka can be used to to apply ML algos, visualize data and transform them.
Wrap up
To sum up, we saw that:
- Analytics reports will tell you what is the distribution of your audience attributes given a goal, but cannot let you predict if a visitor is likely to reach that goal given its attributes.
- Machine learning algorithms need a large number of occurrence based data while GA is designed to provide you few aggregated statistics on a period
- Data Mining is a trial and error process drivable ML tools like Weka
Coming up next
Up to now, you still have nothing in your hands to prototype your first machine learning experiment.
In the next blog-post (edit : here), we'll see :
- How to quickly get event based data without coding on GA Core reporting API
- The basic data transformations you'll need to apply and why
- How to visualize your data with Weka and make your first predictive decision tree